為 infra 工程師而寫的 Claude Code 深度系列。從機制理解到商務治理,繁體中文圈第一套系統性文章。
為 infra 工程師而寫的 Claude Code 深度系列。從機制理解到商務治理,繁體中文圈第一套系統性文章。
為什麼寫這個系列 過去三個月我在工作上密集使用 Claude Code 處理維運任務——從日常巡檢、事件排查、規格撰寫、到跨雲服務的自動化。雖然時間不長,但這段密集的沉浸式經驗讓我意識到兩件事。第一件是,我自己一開始也在事後才意識到,市面上多數談 AI 工具的文章集中在「工具介紹」或「使用教學」的層級,從工程角度拆解運作機制的繁中資源不是那麼容易找。第二件是,從企業維運與合規視角談 AI 助理的繁中資源同樣不多見——這個視角需要結合對 AI 工具的技術理解、對企業資訊架構的實務經驗、以及對合規治理的敏感度,三者剛好同時關心的人不多。 這個系列想填補的,就是這個空缺。我寫的每一篇都有一個共同的預設——讀者是具備工程能力、對效率有要求、同時對合規與治理敏感的專業工作者。不論你是 DevOps、SRE、infra 工程師、還是需要評估 AI 工具的技術主管,這個系列希望提供一條相對完整的脈絡,而不是零散的技巧。 系列地圖 整個系列由十篇文章組成(第 8-10 篇正在準備中)。前半部(第 1-5 篇)聚焦於機制理解,幫你建立對 Claude Code 運作方式比較深入的認知。後半部(第 6-10 篇)轉向決策與治理,處理使用過程中的工具選擇、成本、商務、權限、以及跨階段的工作流整合。 **第 1 篇《為什麼 Claude Code 是不一樣的 AI 工具》**是系列的地基。許多人把 Claude Code、Copilot、Cursor、ChatGPT 當成同類產品比較,我覺得這是類別上的混淆。這一篇先把座標系統建立好,讓你看到 Claude Code 屬於一個完全不同的工具類別——Agentic CLI——它解決的問題、要求的使用方式、帶來的價值,跟 IDE 外掛式的 AI 助理有本質差異。 **第 2 篇《Agent Loop:AI 助理的心跳機制》**開始進入技術核心。你以為自己在「跟 AI 對話」,實際上是在驅動一個迴圈。這個認知的轉換很關鍵——不懂 Agent Loop,後面所有的成本優化、context 管理、權限設計都會是黑盒魔法。這一篇用一個具體情境,拆解從你按下 Enter 到 AI 回應完成之間的六個階段。 **第 3 篇《四層 Context 壓縮:200K 窗口的真實調度》**是整個系列技術密度較高的一篇。Context 管理是 Claude Code 設計上比較精巧、也比較容易被誤解的一塊,而且直接影響使用體驗。這一篇完整拆解四層壓縮管線——Pre-pipeline、Snip Compact、Micro Compact、Context Collapse、Auto Compact——並分析何時用哪一層、為什麼這樣排序、以及 1M context 出現之後這套系統發生了什麼變化。 ...
本文為《AI 輔助維運工程:從 Claude Code 機制到企業落地》系列第 1 篇。全系列共十篇(第 8-10 篇正在準備中),從原理到落地完整涵蓋。 一個工程師的困惑 我手上已經有 GitHub Copilot,每天打開網頁版 Claude 問東問西,偶爾用 Cursor 改 code。為什麼還要在 terminal 裡裝一個 Claude Code? 這是我一開始的疑問。我猜很多人也是。 答案我花了一段時間才真的想清楚:這些工具不是在競爭同一件事,它們解決的根本就是不同類別的問題。把它們擺在一起比較,就像把「螺絲起子、電鑽、CNC 加工機」拿來問「哪一個比較好?」——問題本身就設定錯了。 這篇文章不是要告訴你 Claude Code 比其他工具「更好」,而是要說清楚它是什麼種類的東西。理解這件事之後,後面幾篇的技術細節你才能真的吸收。 先把座標定好:四種工具在做四件事 我用自己的理解把市面上常見的 AI coding 工具分成四類。分類標準是「它主要在幫你做什麼層級的事」: 工具類型 代表 主要幫你做 你扮演的角色 行內補全 GitHub Copilot 當你在打字,它猜你下一行 駕駛 對話助手 Claude.ai 網頁版 / ChatGPT 你問問題,它回答 提問者 IDE 協作者 Cursor / Windsurf 在你的編輯器裡幫你改多個檔案 副駕駛 Agentic CLI Claude Code / Codex CLI 在終端裡自主完成任務 指揮官 這張表不是要排名高下。每一種工具都有它最適合的場景:寫前端切版,Copilot 行內補全超好用;討論一個演算法,網頁版 Claude 反而最合適;想在 IDE 內一次改 20 個檔案,Cursor 是最舒服的選擇。 ...
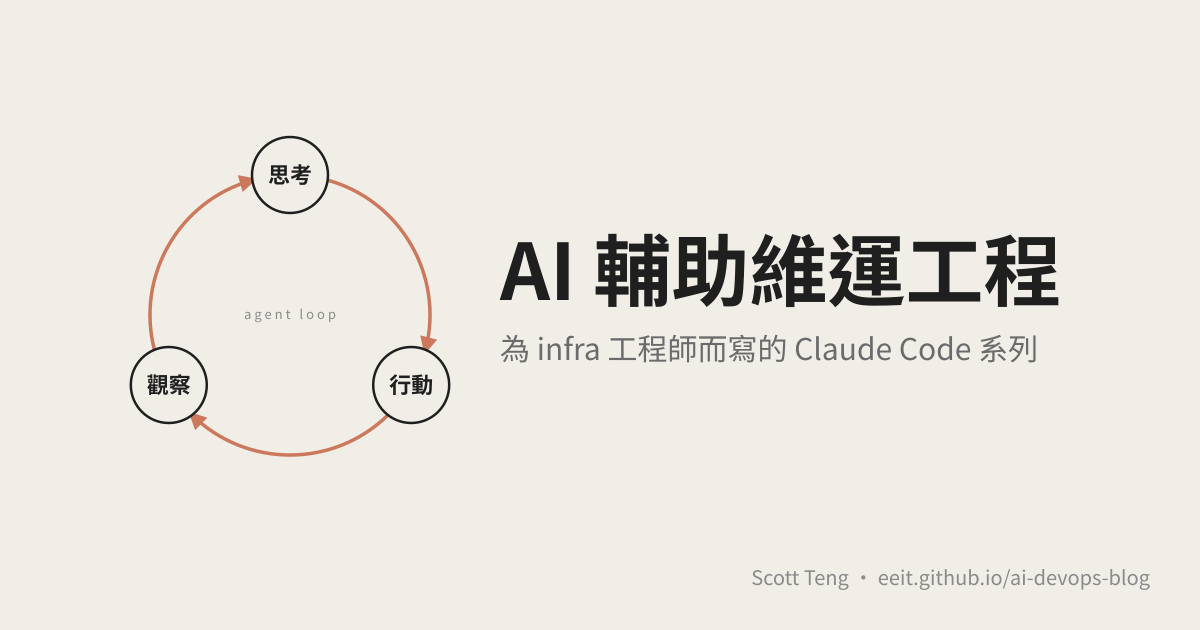
本文為《AI 輔助維運工程:從 Claude Code 機制到企業落地》系列第 2 篇。前一篇談了為什麼 Claude Code 是不一樣的工具,這一篇開始進入它的運作核心。 為什麼先懂這個 你可能以為你在「跟 Claude Code 對話」。 實際上,你是在驅動一個迴圈。 這個差異不是修辭。搞懂之後,後面所有的疑問都會有答案: 為什麼同樣一句話,有時候 3 秒結束、有時候跑 5 分鐘? 為什麼 token 帳單會爆炸,而且完全看不出錢花在哪? 為什麼一個任務進行到一半會卡住? 為什麼「thinking…」有時候真的在想,有時候只是在處理資料? 這些問題的根源都在 Agent Loop。這篇文章不是教你怎麼用 Claude Code,是要你建立一個關於它運作方式的心智模型,這個模型會貫穿整個系列。 三句話版本的 Agent Loop 如果要用最精簡的方式描述,Claude Code 做的事情就是這三件: 接收輸入,組裝成模型看得懂的 prompt 呼叫模型,拿到回應 判斷要不要繼續,要繼續就執行工具,拿結果回到第 1 步 聽起來很簡單。但魔鬼在細節裡,尤其是第 3 步的「判斷要不要繼續」。這個判斷讓 Claude Code 從「問答工具」變成「任務執行者」。 一次對話實際發生了什麼 我們用一個具體情境拆解:你在 Claude Code 裡輸入「幫我看看今天早上 nginx 的錯誤日誌,有沒有 5xx 的異常」,然後按下 Enter。 接下來發生的事情,可以分成六個階段。 階段一:你按下 Enter 之後的 0.1 秒 訊息送進 Claude Code 的處理管線之前,先經過一道輸入處理: ...
本文為《AI 輔助維運工程:從 Claude Code 機制到企業落地》系列第 3 篇。前一篇談了 Agent Loop,這一篇會進入這個系列裡技術密度較高的主題。如果你之前對「為什麼我的 context 會突然不夠用」、「/compact 到底何時該按」、「Claude 為什麼突然開始忘東西」這些問題感到困惑,這篇會把這些機制一起拆開來看。 為什麼需要整整一篇寫這件事 前一篇講了 Agent Loop —— 每一輪模型呼叫,都要把整段對話歷史送進 API。 這件事在對話短的時候沒人會在意。但當任務開始變長: 一個跨 10 個檔案的重構 一次完整的事件排查 一份規格文件從草稿到定稿的對話 你會發現一個令人焦慮的現象:Claude Code 開始回應變慢、帳單變貴、有時候甚至主動告訴你「context 快滿了」。 根本原因在於 context window 的物理上限。以目前主流的 Claude 模型來說: 舊一代模型(例如 Sonnet 4、Sonnet 4.5):上限 200K tokens 新一代模型(Opus 4.6 / 4.7、Sonnet 4.6):上限提升到 1M tokens,且自 2026 年 3 月起已 GA 無溢價 聽起來 1M 似乎什麼煩惱都沒了?實際沒這麼簡單 —— 稍後會有一節專門談「1M 不是萬靈丹」。這裡先建立一個共識:不論你用哪一代模型,壓縮管線的設計原理都一樣,只是觸發閾值不同。 一個五小時的維運任務,搭配幾份被讀進 context 的大型設定檔,即使在 200K 窗口也會消耗得比你想像快。 如果 Claude Code 對這件事不做任何處理,用戶體驗會是這樣: ...
本文為《AI 輔助維運工程:從 Claude Code 機制到企業落地》系列第 4 篇,分上下兩集。上集聚焦 Sub-agent 的技術機制,下集談 Agent Team 的分工設計與兩者的搭配。 兩個被混為一談的概念 我在跟同事討論 Claude Code 的時候,常發現同一個場景被用兩種完全不同的方式描述。有人會說「我請 Claude 派了幾個 subagent 去平行跑搜尋」,另一個人會說「我用多個 agent 分工處理這個任務」。聽起來像同一件事,但這兩句話背後指的是兩個不同層級、解決不同問題的機制。把它們視為同義詞,是我自己一開始也踩過的盲點。 為了把這件事講清楚,這篇我只談 Sub-agent,下一篇才談 Agent Team。我自己摸索的觀察是:兩者雖然名字相近,但設計目的、壽命、使用情境、對 token 的影響都完全不同。上篇主要拆解 Sub-agent 作為 Claude Code 內部的執行機制,下篇處理 Agent Team——對我而言它比較不是技術問題,是工程治理問題。 先從一個比喻開始 想像你是一位主編,在寫一份重要的專題報告。這份報告需要你去查證五個不同來源的資料:翻三份期刊、比對兩份歷史檔案。你手上有五個實習生可以派遣,而你要盡快把報告完成。 你會怎麼做?最笨的方法是自己一個接一個去查,五件事做完再開始寫。聰明一點的做法是:把這五件查證任務同時交給五位實習生,你就在辦公室繼續思考結構,等他們陸續帶著結果回來。每位實習生只需要知道你交辦的那一件事的上下文,不需要理解整份報告的全貌。他們查完、回報、任務結束,這位實習生對你而言就「用完了」——下一份報告如果還要查證,會派遣新的實習生,不是同一個人。 這就是 Sub-agent 的運作本質。當 Claude Code 遇到一個可以切割的子任務,它會衍生出一個「分身」去處理這件事。分身的生命週期就只有這個任務——做完回報給主 agent,然後就消失。它不會被記住、不會累積經驗、也不會跟其他分身協調。它的存在目的只有一個:讓主 agent 能專注在整體決策,不被瑣碎的子任務細節吃掉注意力與 context。 理解這點之後,有一個重要觀念要先立:Sub-agent 是 Claude Code 給自己用的機制,不是給你用的。你不用親自去「指派」sub-agent,大多數時候 Claude Code 會判斷什麼時候派、派幾個、派去做什麼。你頂多是透過 prompt 暗示它「這件事可以平行查」,實際要不要開分身,是它決定的。 你一直在用 Sub-agent,只是沒發現 當你在 Claude Code 裡請它「幫我找出所有使用 deprecated API 的檔案」,你看起來只是提了一個問題。但如果你打開 verbose 模式觀察,會發現事情沒那麼簡單。Claude Code 很可能會先開一個名為 Explore 的分身,這個分身專門做唯讀搜尋,不會修改任何東西。它會用 grep、glob 這些工具快速掃過整個 codebase,把結果彙整成一份清單回傳。主 agent 拿到清單後,才開始做後續的分析或修改。 ...
本文為《AI 輔助維運工程:從 Claude Code 機制到企業落地》系列第 4 篇下集。上集把 Sub-agent 當技術機制拆透了,這一集要談的 Agent Team 完全不是同一回事——它是一套設計,不是一個功能。讀完這兩集,你會發現這兩個常被混為一談的詞,其實解決的是完全不同層級的問題。 如果 Sub-agent 是跑腿分身,那 Agent Team 是整個劇組 我們先用一個熟悉的情境作為入口。 想像你要拍一部微電影。你手上有一個非常能幹的助理,他隨時可以幫你跑腿——去買道具、去聯絡場地、去印劇本。他是你的分身,你派他去做什麼他就做什麼,事情完成就回來待命。這個能幹的助理,就是上集我們講的 Sub-agent。他讓你這個導演可以專心拍戲,不被瑣事打斷。 但是等一下。你有了跑腿助理,就能拍出一部好電影了嗎? 顯然不行。一部電影需要編劇寫劇本、演員演出、攝影師掌鏡、剪接師整理素材、導演統合全局。這些人各有專業,各有分工,而且有一件非常重要的事情——他們互不越界。剪接師不會衝進拍攝現場改劇本,演員不會在剪接室擅自決定鏡頭順序,編劇不會在後製階段要求演員重演。這種「各司其職、互不越界」的紀律,是一部作品能完成的根本保證。 這個「劇組」,就是我們這集要談的 Agent Team。 它跟 Sub-agent 完全不是同一回事。跑腿助理是一次性的,做完就消失;劇組成員是長期存在的角色,一部戲之後還有下一部。跑腿助理沒有專業分工,派他去買水跟派他去印劇本沒差別;劇組成員有明確的專業邊界,編劇做不來演員的事,反之亦然。跑腿助理靠執行效率創造價值;劇組成員靠分工紀律創造價值。 讀到這裡你可能會問:我用 Claude Code 就是一個人對著終端敲指令,哪來什麼「劇組」?這個問題正是這篇要回答的。我自己在 POC 中發現,哪怕是一個人在用,Claude Code 內部的每次思考切換,其實都對應到某種「角色切換」——只是這件事我一開始也沒意識到。沒意識到的時候,作品品質容易忽好忽壞,而且自己也說不清原因。 一個人當編劇、導演、演員、觀眾,會發生什麼? 讓我們往下挖一層。為什麼劇組一定要分工?為什麼不能一個人包辦所有角色? 答案不是「做不完」。一個有才華的創作者,確實可以自編自導自演自剪,獨立電影的歷史上不乏這樣的例子。我的觀察是,問題在於一個人同時扮演多個角色時,思維模式會互相汙染。 當你寫劇本時,你的大腦是「建設性」的——怎麼把這個故事說得精彩?怎麼讓衝突升溫?怎麼讓角色有弧度?這個思考模式是發散的、樂觀的、為可能性而興奮的。現在你寫完了,進入演出階段。你要把自己寫的台詞演出來。這個思考模式是收斂的、投入的、為情緒真實而努力的。兩種思考模式之間本來就存在矛盾——編劇看到的是「可能性」,演員看到的是「限制」。 真正的挑戰在剪接室。你剛演完這場戲,覺得自己演得不錯。但剪接階段你要變成審查者,用最冷酷的眼光看剛才的演出,判斷它到底好不好、該不該保留。但你的大腦還停留在演員模式——還在回味剛才的情緒、還對自己的表演有感情、還會下意識地為自己辯護。這時候你下的剪接決定,品質會差。 這不是意志力的問題。認知模式的切換需要時間,而切換不完全的時候,前一個模式的殘留容易影響下一個判斷——這是我自己在 POC 中反覆觀察到的現象。 現在把這個觀察搬到 AI 助理的世界。你給 Claude Code 一個任務:「幫我寫一個處理 CSV 的 Python 腳本,記得要有完整的錯誤處理和測試。」它開始工作。寫腳本時,它進入「建設者」模式——怎麼讓程式優雅、怎麼處理各種 edge case、怎麼結構化。寫完之後,你說:「幫我 review 一下這段程式碼。」它立刻切換成「審查者」模式,但它還記得自己剛才為什麼這樣寫,還會下意識地為自己的設計辯護。我自己遇到過的狀況是:每一行 review 都寫「這段程式碼清楚地實現了…」,沒有真正的批判。 這種狀況有一個現成的詞,叫「球員兼裁判」。這不是罵人,是描述一種結構性的困境——同一個主體同時扮演相互制衡的角色,制衡就失效了。Claude Code 碰到的是類似的困境。它是非常強的模型,但它也受限於同一次對話裡的認知慣性。 Agent Team 要解的,就是這個困境。做法不複雜:強制切換角色。不是用意志力切換,是用系統設計切換。每個角色有自己的職責、自己的禁止清單、自己的思維模式定義;切換時有明確的儀式,讓前一個角色的殘留徹底清除;切換後用的是一份全新的、專屬這個角色的指令集。這不是在 prompt 上寫「現在你要扮演一個嚴格的 reviewer」就了事——那樣的「偽切換」我自己試過效果有限,因為缺少架構層級的強制力。我覺得有效的角色切換,像演員從劇本室走到片場,有空間位置的改變、有造型的改變、有整個氣氛的改變。 ...
本文為《AI 輔助維運工程:從 Claude Code 機制到企業落地》系列第 5 篇。系列前半部講機制(Claude Code 怎麼運作、Agent Loop 怎麼跑、Context 怎麼管理、Sub-agent 怎麼分工、Agent Team 怎麼治理),這一篇開始進入後半部——你站在使用者或主管的角度,要做哪些實際決策。第一個決策就是關於錢。 當帳單比你預期的高出五倍 我想先請你想像一個場景。 一位工程師最近迷上 Claude Code。他每天早上打開,下午處理幾個 ticket,晚上偶爾還會用它整理週報。感覺很滿意,生產力明顯提升。月初收到 API 帳單的時候,他愣了一下——比他預期的高出大約五倍。 他不相信。回頭去看使用紀錄,確認沒有異常的大量呼叫、沒有惡意濫用、也沒有帳號被盜用的跡象。每天該做的事他都記得,那些事情理論上不該產生這麼多 token 消耗。但帳單就是擺在那裡。 這個情境是很多 Claude Code 新使用者的共同經驗。如果你也遇過、或擔心自己會遇到、或身為主管在審視團隊 AI 採購預算時心裡有這種疑慮——這篇文章就是為你寫的。 我會先花點時間建立「token 經濟學」的基礎觀念,然後解釋為什麼你以為自己理解的成本模型,其實跟實際發生的事情有出入。再來談 Prompt Cache 這個我自己一開始也忽略的助手、Claude Code 暗中在幫你省錢的各種設計、以及你自己能主動做的節省策略。讀完之後,我希望你能對著帳單,比較容易指出每一塊錢花在哪、哪些可以減少、哪些不能省。 先回到最基本:Token 是什麼,為什麼按這個計費 很多人聽過 token 這個詞,但沒真的弄清楚它是什麼。這裡花一點時間講清楚,因為後面所有的計算都建立在這個基礎上。 Token 是大語言模型用來處理文字的基本單位。你可以把它想成「字」,但不完全等於中文的一個字、也不完全等於英文的一個單字。實際上它比較像字元片段——一個常見的英文單字(例如 “the”)是一個 token,一個較長的單字可能被拆成兩三個 token,中文的一個字大約是一到兩個 token。 給你一個粗略的換算:一個中文字大約是 1 到 2 個 token,一個英文單字平均是 0.75 個 token。一頁 A4 中文文件大約包含 2000 到 3000 個 token。一篇 3000 字的文章大約是 4000 到 6000 個 token。這樣你看到「一百萬 tokens」的時候,大概能感覺出那是什麼規模——相當於一本中等厚度的書。 ...
本文為《AI 輔助維運工程:從 Claude Code 機制到企業落地》系列第 6 篇。上一篇談 token 經濟學——怎麼算清楚一次 session 的錢。這一篇談更中觀的問題:一整個 SSDLC 流程跑下來,每個階段該用哪個 Claude 入口? 這個問題有兩個陷阱。第一個,你會被誘惑去問 Claude 本身——「你適合還是對方適合」——然後得到一份結構完整、理由清楚、但可能帶有系統性偏誤的答案。第二個,你會以為這個選擇有標準答案——其實選擇取決於你的工作型態、當下任務的條件、甚至你今天的認知狀態。 這篇要處理的就是這兩個陷阱。路徑是:從一次臨時起意的對照實驗開始,看 Claude 在評估自己時會出現什麼偏誤;再倒回來建立一個獨立於工具本身的判準;最後用這個判準重讀自薦文,你會自己看見該怎麼選。 一個臨時起意的對照實驗 前陣子我在 Claude Code 裡寫規格,寫到一半停下來——這個訪談,在 Claude.ai 也能做。 兩邊跑的是同一個模型,但環境不一樣:Claude Code 接我的 repo 跟 terminal,Claude.ai 有 Project Knowledge 跟跨日對話。同一個模型,不同平台,做出來的分析品質會不會不一樣? 這是個可以測的問題。 我順手做了個對照實驗:先問 Claude Code「你跟 Claude.ai 誰適合做這個訪談」,再把同樣的問題丟給 Claude.ai,比兩邊。 Claude Code 的回答 節錄: 核心理由:(1) 我的工具鏈原生支援 (2) 輸出直接寫進 repo (3) 下一階段無縫接軌 我的推薦:Claude Code 選項:A(Claude Code,我推薦)/ B(先 Claude.ai 探索,再回 Claude Code 寫進 repo,折衷)/ C(純 Claude.ai,最不推薦) 乍看很有結構、理由清楚、選項排好優先級,差點就按 A。但我多看了它給的對比矩陣兩眼,發現幾格事實錯了——說 Claude.ai「無檔案存取」「不能呼叫 skill」,但這兩件事 Claude.ai 現在都做得到(Project Knowledge、MCP connector、skill 機制),我平常就在用。三格裡有兩格錯,錯的方向一致——都讓 Claude.ai 看起來比實際能力差。 ...
本文為《AI 輔助維運工程:從 Claude Code 機制到企業落地》系列第 7 篇。前兩篇分別處理了 token 成本(第 5 篇,如何在一個方案內省錢)和 SSDLC 工具選擇(第 6 篇,不同階段該用哪個入口)。這一篇處理最上層的商務決策:**該選哪個方案?**對我而言,選對方案的一次性決策,常常比後續一連串的技術優化更值得提早花時間想清楚。 開場:選型可能是你最容易忽略的省錢決定 我想先請你回想一件你可能做過的事。 你換手機資費方案的時候,應該有那種經驗——某天你靜下心來,把家裡三支手機的每月帳單加起來,發現一年竟然多花了好幾千塊,只因為當初沒仔細比較方案。後來你花一個下午研究、比較、換方案,從此每月省下兩千元。一個下午的研究,換來全年兩萬四的節省。 你省下的錢不是因為你講電話講得變少,而是因為選對了方案。 這個觀察對於 AI 服務的使用一樣成立。我自己在 POC 初期花了大量心力優化 CLAUDE.md、精調 MCP 設定、學習 /compact 的時機——這些都有價值。但我也看過(包括我自己)用錯方案的情境:一個個人 Pro 帳號,可能其實多花了錢,也少了 SSO、費用控管,預設還讓對話被拿去訓練模型。這些問題不是技術優化能解決的,只能透過選對方案來解決。 所以這一篇我們先不談技術,先談商務決策。Anthropic 目前提供四種 Claude 服務管道,每一種的計費方式、功能範圍、資料處理政策都不同。我希望這篇可以幫你比較容易判斷自己的情境屬於哪一類、適合什麼選擇,以及背後的理由。 四種方案的全景地圖 先建立整體感。Anthropic 的四種服務管道是這樣的架構: 個人版(Pro / MAX)。針對單一使用者的方案,Pro 每月大約二十美元(寫這篇時的公開定價),MAX 則依使用量分為每月一百或兩百美元。這通常也是初次接觸 Claude 時最常被使用的方案——你在瀏覽器打開 claude.ai,登入你的個人帳號,就是在用 Pro 或 MAX。 團隊版(Team Plan)。針對五到一百五十人的小中型組織。Standard seat 每人每月二十美元(年繳)或二十五美元(月繳),Premium seat 每人每月一百美元(年繳)。相較於個人版,它加入了 SSO、管理者後台、費用控管、M365/Slack/Google 整合等組織管理功能。2026 年以來 Anthropic 對這個方案做了大量功能強化,現在它已經是一個相當完整的組織級方案。 Enterprise。針對更大規模的組織,分為自助版(二十人起)和業務協助版(五十人起)。計費結構不同——每人每月二十美元的平台存取費,加上實際用量按 API 費率另計。這個結構意味著你的總成本取決於實際使用量,不是固定值。Enterprise 比團隊版多出的關鍵功能是稽核合規類——audit logs、Compliance API、IP allowlisting、自訂資料保留政策。 API。針對開發者與系統整合。這裡沒有「座位費」,完全按 token 使用量計費。你拿到一組 API Key,放進你的應用程式或自動化腳本,每一次呼叫按實際消耗計算。這是 Claude Code 在命令列背後用的機制,也是所有「把 Claude 整合進自家產品」的團隊在用的方式。 ...